О том, как мы ворпсиманием теcкт / Хабр
Помните, в интернете, году этак в 2003, проходила картинка, в которой сообщалось, что неважно в каком порядке идут буквы в слове, лишь бы первая и последняя были на местах, а остально мозг сам скомпонует и вычленит смысл. Вот оригинальный текст:
По рзелульаттам илссеовадний одонго анлигйсокго унвиертисета, не иеемт занчнеия, в кокам пряокде рсапожолены бкувы в солве. Галвоне, чотбы преавя и пслоендяя бквуы блыи на мсете. Осатьлыне бкувы мгоут селдовтаь в плоонм бсепордяке, все-рвано ткест чтаитсея без побрелм. Пичрионй эгото ялвятеся то, что мы чиатем не кдаужю бкуву по отдльенотси, а все солво цликеом.
В английском варианте это звучало так:
Arocdnicg to rsceearch at Cmabrigde Uinervtisy, it deosn’t mttaer in waht oredr the ltteers in a wrod are, the olny iprmoatnt tihng is taht the frist and lsat ltteer are in the rghit pcale. The rset can be a toatl mses and you can sitll raed it wouthit pobelrm.Tihs is buseace the huamn mnid deos not raed ervey lteter by istlef, but the wrod as a wlohe.

Попытка поэкспериментировать с разными текстами показала, что с русским языком все не так безоблачно, как с английским и алгоритм эффективного и readable-перемешивания все-таки немного другой.
Cсылаются на труды некого Matt Davis, который в свою очередь, отсылает к Rawlinson, G. E. аж 1976 года (summary).
Я не поленился и написал простенькую программу, которая обрабатывает тексты. Откуда выяснил, что не совсем так, как заявлялось, но истина где-то рядом.
Так вот, если менять середину слов совсем произвольно, то получится следующее:
На Оклисмпйиих играх ссяоислтоь жскиене коныандме срнноваовеия по сооипвртнй гмксинатие Зутолою медлаь Игр золвавеаа сранобя США соеабощт оалцьифниый сйат Оалпимиды Втооре мтесо зяални птеьртлиадисцнвеы роскосисйй кдаомны котраоя вриыгала для ннаьиоцонлай сбнроой вротое срербео среребо сонобрй Риосси пнслриеа теактлотжлеяа Свлтнаеа Цавакреуа Брвооунзю нарадгу пиучолли ринскымуе гксаминти.

В принципе, понятно, но стоит взять слова подлиннее, как текст становится плохоузнаваемым:
Влртачеси писунрак в Калокагнсидрним мосрком рынбом потру коротый в эти дни очмател 65-леите. В честь пкардниза порт пдерепнос падорок калидингнацрам и риршазел снобывдой пхород на торритерию. Все жищеюлае смогли посетить Кзерушнретн. Такая возтонжосмь вадепаыт не чатсо. Как праливо посьятдня на борт Кзреуншртена пинусрака мугот гости морнудежадных мирксох праднзиков в инанртосных потрах а желити Каланинргида.
Зато если взять за правило сохранять позиции согласных и гласных букв, свободно меняя между собой отдельно гласные и согласные, то результат получается слегка более читаемым и понятным при том же хаосе:
На Окислийпмих играх сяссоотиль жикнсее кыдоннмае совинроневая по снирповтой гимнастике Зотолую мадель Игр залаовева сборная США сообщеат олиьиацнфый сайт Олампииды Второе метсо заняли пцидвларетеьнситы рискоссйой кадомны которая ваилрыга для наьоонинлцай сронбой второе серербо себерро снорбой России псинелра тотелаеклятжа Стевлана Цавураека Бвонзорую надрагу почулили рунимскые гиснатмки.

и для второго текста
Влрчасети писанрук в Кигидонрнасклам моксром рыбном порту который в эти дни отмачел 65-литее. В четсь пкинзрада порт ппедорнес пародок кагиданнларцим и разширел сдывонбой проход на торриритею. Все жалиещюе сголми писетоть «Кзерушнретн». Такая вотмонзосжь вапедаыт не часто. Как пвиларо пяьсоднтя на борт пикарсуна мугот готси мырдожанундех мирскох пзанрдиков в инантронсых партох а желити Каниларгдина видят мачты «Кзерушнрента» токьло через огдару потра.
Теперь сделаем еще небольшое изменение — добавим максимальное расстояние между переставляемыми символами в 3 символа, чтобы согласная с начала слова не улетала в его конец. Также добавляем учет того, что более одного раза символы переносить нельзя. В итоге выходит текст, из которого уже почти все понятно:
Всртечали пасурник в Калиниргнаксдом мосрком рыбном порту котырой в эти дни отмечал 65-телие. В четсь пзардника прот преподнес подарок киналигнрадцам и рарзешил свободный пхород на тертирорию.
 Все желюащие сгомли посетить Крунезштерн. Такая возможнотсь выпадеат не чатсо. Как пвирало подняться на борт парусника могут гости междуронандых морских пзардников в инотсранных потрах, а жилтеи Киналигнрдаа видят мачты Кзерутшнерна тоьлко через оргаду порта.
Все желюащие сгомли посетить Крунезштерн. Такая возможнотсь выпадеат не чатсо. Как пвирало подняться на борт парусника могут гости междуронандых морских пзардников в инотсранных потрах, а жилтеи Киналигнрдаа видят мачты Кзерутшнерна тоьлко через оргаду порта.В итоге выходит, что для русского языка не все так безоблачно, как для английского, с его короткими словами. Но если немного поменять алгоритм, общая идея все-таки работает.
Интересно, есть ли возможность внести еще шума в середину слова с сохранением читабельности и понятности?
UPDATE:
torkve пишет:
Мне кажется, правильнее попробовать сделать что-то вроде Вашего последнего алгоритма, только немножко развить идею:1. Фиксируем первый и последний символы слова.
2. Из оставшихся берём первые три символа, произвольно перемешиваем.
3. Из полученной новой тройки фиксируем первые два.
4. Повторяем пункт 2, пока незафиксированные символы не кончатся.

Я практически так и сделал, но фиксировать в п. 3 стоит не первые два, а первые три. Иначе одна буква может пропутешествовать до конца слова. Вот что получилось:
Врстаечли парусинк в Клаининагрдском мсроком рбыном потру ктоорый в эти дни отемачл 65-лтеие. В чтсеь пазрдника порт ппредонес паодрок киалнинргацдам и рзраиешл сбовондый проход на трретоиирю. Все желающие сгомли поестить Кзрушенетрн. Ткаая взомжностоь впыааедт не чатсо. Как парвило пдонтьяся на брот пруаинска моугт гстои междунадроных мосрикх праздинков в инсотранных протах, а жтиели Калииннагрда вядит мачты Курзнештерна тльоко через ограду пртоа.
Выходит ничего так.
UPDATE2. Решил проверить, что будет, если убрать практически все гласные — не трогать начала и концы слов. Ведь в том же арабском или иврите их практически нет — обходятся согласными. Вот что выходит с произвольного текста из «Дворянского гнезда» Тургенева:
Мрья Дмтриевна в млдсти пльзвлсь рптцией млнькой блнднки; и в птьдст лт чрты ее не бли лшны приятнсти, хтя нмнго рспхли и спллсь.
 Она бла блее чвствтльна, нжли дбра, и до зрлх лт схрнла инстттские змшки; она изблвла сбя, лгко рздржлсь и дже плкла, кгда нршлсь ее првчки; зто она бла очнь лсква и лбзна, кгда все ее жлния исплнлсь и нкто ей не пркслвл. Дм ее прндлжл к чслу приятнейшх в грде. сстояние у ней бло всьма хршее, не стлько нслдствнное, склько блгприобртнное мжм. обе дчри жли с нею; сн всптвлся в однм из лчшх кзннх звдний в птрбрге.
Она бла блее чвствтльна, нжли дбра, и до зрлх лт схрнла инстттские змшки; она изблвла сбя, лгко рздржлсь и дже плкла, кгда нршлсь ее првчки; зто она бла очнь лсква и лбзна, кгда все ее жлния исплнлсь и нкто ей не пркслвл. Дм ее прндлжл к чслу приятнейшх в грде. сстояние у ней бло всьма хршее, не стлько нслдствнное, склько блгприобртнное мжм. обе дчри жли с нею; сн всптвлся в однм из лчшх кзннх звдний в птрбрге.Удивительно, но без гласных понятно абсолютно все. Причем текст ужался на 34 процента.
Главная страничка сайта: http://nikkka.ru | ||
| Все великие открытия были сделаны по ошибке… | ||
 gif» cellspacing=»0″ cellpadding=»0″ border=»0″> gif» cellspacing=»0″ cellpadding=»0″ border=»0″> | ||
| ||
| ||
Артефакт из сети:: проект Олега ГорскогоВНИМАНИЕ!!! НЕКОТОРЫЕ МАТЕРИАЛЫ САЙТА ТОЛЬКО ДЛЯ ВЗРОСЛЫХ!!! Если Вы не достигли должного возраста, либо Вы не терпимы, к порою «жесткому» слову, картинке Лучше воздержаться от просмотра и перейти на другой сайт! Многие материалы взяты в сети и если вдруг, у Вас возникли вопросы по копирайту (авторству), представленных материалов: | |||||||
| |||||||
Не имеет значения в каком порядке расположены буквы в слове.Прикольно! И ведь это именно так! | |||||||
| по рзезульаттам илссеовадний одонго анлигйсокго унвиертисета, не иеемт занчнеия, в кокам пряокде рсапожолены бкувы в солве.  галвоне , чотбы преавя и пслоендяя бквуы блыи на мсете. осатьлыне бкувы мгоут селдовтаь в плоонм бсепордяке, все-рвано ткест чтаитсея без побрелм. пичрионй эгото ялвятеся то, что мы не чиатем кдаужю бкуву по отдльенотси, а все солво цликеом | |||||||
| Ниже приведена форма (скрипт) для работы с регистром текста. Вы можете использовать этот прикольный текст для пробы работы данного скрипта. Сам скрипт выложен в HTML коде этой странички. Эксперементируйте! Правовая инфа: Mutter.boom.ru — самая полная коллекция JavaScript | |||||||
| Вставьте текст в окно (или напечатайте): | |||||||
| |||||||
 (См. также — Политику Сайта)
(См. также — Политику Сайта) Приколы. Перлы из школьных сочинений.»::
Приколы. Перлы из школьных сочинений.»::
| ||
| ||
 ПРОДВИЖЕНИЕ САЙТА
ПРОДВИЖЕНИЕ САЙТА gif» alt=»Нижняя подложка»>
gif» alt=»Нижняя подложка»>При копировании материалов,
открытая гипертекстовая ссылка обязательна!!!
© 2008–2022, Разработка сайта, продвижение сайта: Design by Gorskii Oleg
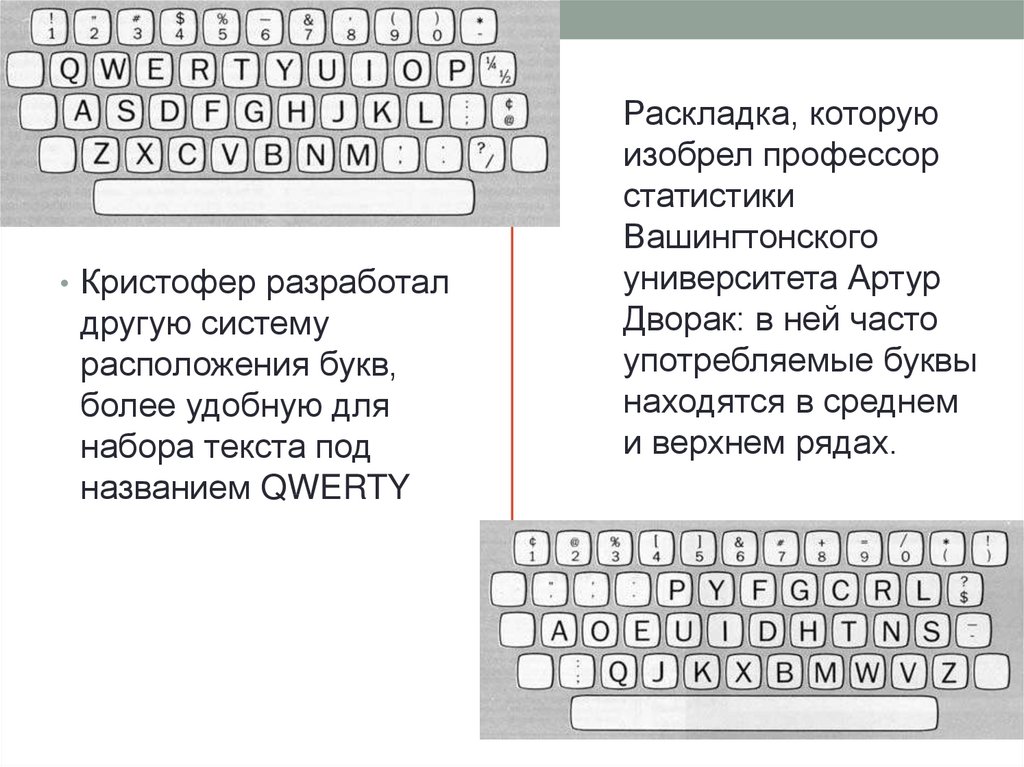
Почему мы понимаем текст, в котором переставлены буквы?
Наверняка вы видели такие тексты в интернете — картинку со словами, буквы в которых переставлены местами и смысл которых вы по-прежнему можете понять
Наверняка вы видели такие тексты в интернете — картинку со словами, буквы в которых переставлены местами и смысл которых вы по-прежнему можете понять.
По рзелульаттам илссеовадний одонго анлигйсокго унвиертисета, не иеемт занчнеия, в кокам пряокде рсапожолены бкувы в солве. Галвоне, чотбы преавя и пслоендяя бквуы блыи на мсете. Осатьлыне бкувы мгоут селдовтаь в плоонм бсепордяке, все-рвано ткест чтаитсея без побрелм. Пичрионй эгото ялвятеся то, что мы чиатем не кдаужю бкуву по отдльенотси, а все солво цликеом.
Галвоне, чотбы преавя и пслоендяя бквуы блыи на мсете. Осатьлыне бкувы мгоут селдовтаь в плоонм бсепордяке, все-рвано ткест чтаитсея без побрелм. Пичрионй эгото ялвятеся то, что мы чиатем не кдаужю бкуву по отдльенотси, а все солво цликеом.
С одной стороны, это похоже на правду. Однако научное объяснение, которое стоит за этим, куда сложнее.
Утверждение, которое стоит за этой картинкой, основывается на том, что человеческий мозг может воспринимать смысл слова целиком, независимо от порядка букв — главное, чтобы первая и последняя были на месте. Якобы об этом писали ученые из Кембриджского университета.
Но это не совсем правда, во всяком случае только часть правды. У наблюдаемого явления есть свое название: тайпогликемия. Оно существует благодаря тому, что наш мозг опирается не только на то, что мы видим, но еще и на то, что мы ожидаем увидеть.
В 2011 году ученые из Университета Глазго обнаружили, что, когда объект затемнен или размыт для зрения, человеческий мозг способен достроить его детали и заполнить лакуны при помощи ранее увиденных образцов. Текст — это только часть истории.
Текст — это только часть истории.
Первые исследования на эту тему провел Грэхэм Роулинсон из Ноттингемского университета еще в 1976 году. Он провел 16 экспериментов и убедился в том, что люди могут читать слова с перепутанными буквами, однако у этого есть множество нюансов. Например, человек куда проще воспринимает короткие слова и не может сразу понять слово, если перепутаны не соседние буквы, а расположенные друг от друга на расстоянии (сравните: «прболема» и «перболма»). Также гораздо лучше люди воспринимают слова в контексте (сравните: «прбоелму» и «эут прбоелму лгеко ршеить»). Если целиком поменять все буквы в слове, кроме первых и последних, то понять оригинальное слово станет совсем невозможно («побрмела»).
Вы можете сами попробовать поменять слова в предложении разными способами и показать их друзьям — насколько просто ваш текст будет легко прочесть? Так вы убедитесь в том, что когнитивные процессы, которые стоят за тем, как мы достраиваем образы и опознаем слова, намного сложнее, чем кажутся на первый взгляд.
На сайте могут быть использованы материалы интернет-ресурсов Facebook и Instagram, владельцем которых является компания Meta Platforms Inc., запрещённая на территории Российской Федерации
Расскажите друзьям
- Наука против природы
Ученые отредактировали гены, чтобы сделать пиво вкуснее
- Раскопки
- Что было раньше
В египетском храме найдена святыня со свидетельствами неизвестных ритуалов
- Съедобное / Несъедобное
- Устройство человека
- Социальное животное
Исследование: вегетарианцы чаще впадают в депрессию, чем мясоеды
- Энергетический переход
Ученые Томского политеха нашли бесперебойный способ получать дешевый «зеленый» водород
- Что было раньше
В ДНК девочки VII века из английского Кента обнаружили 33% западноафриканских генов
Вранье: как его распознать — и надо ли?
Современный карликовый крокодил
Shutterstock
Обнаружены еще два вида вымерших крокодилов, которые охотились на предков человека
Найдены новые доказательства жизни в океане спутника Сатурна
Shutterstock
Ученые: неизвестные бактерии из тающих ледников могут представлять опасность
Shutterstock
Ученые объяснили, почему рыба морской дракон выглядит так странно
Хотите быть в курсе последних событий в науке?
Оставьте ваш email и подпишитесь на нашу рассылку
Ваш e-mail
Нажимая на кнопку «Подписаться», вы соглашаетесь на обработку персональных данных
Психолингвистические данные о скремблированных буквах при чтении .
 Установка может быть полной, и вы можете оставить ее без изменений. Это связано с тем, что люди в своих деосских телах не восстанавливаются в течение долгого времени с помощью истлефа, а рождаются как мир.
Установка может быть полной, и вы можете оставить ее без изменений. Это связано с тем, что люди в своих деосских телах не восстанавливаются в течение долгого времени с помощью истлефа, а рождаются как мир. Вернее…
По словам исследователя (так в оригинале) из Кембриджского университета, не имеет значения, в каком порядке стоят буквы в слове, важно лишь то, чтобы первая и последняя буквы стояли на нужное место. Остальное может быть полным беспорядком, и вы все равно можете прочитать его без проблем. Это потому, что человеческий разум читает не каждую букву отдельно, а слово в целом. Этот текст распространился по Интернету в сентябре 2003 года. Впервые я узнал об этом, когда журналист связался с моей коллегой Сиан Миллер 16 сентября, пытаясь найти первоисточник. Он передавался много раз и, как и большинство интернет-мемов, мутировал по пути. Мне это показалось интересным, особенно когда я получил версию, в которой упоминался Кембриджский университет! Я работаю в отделе познания и наук о мозге в Кембридже, Великобритания, в подразделении Совета медицинских исследований, в состав которого входит большая группа, изучающая, как мозг обрабатывает язык. Если в Кембридже проводится новое исследование по чтению, я думал, что должен был услышать о нем раньше…
Если в Кембридже проводится новое исследование по чтению, я думал, что должен был услышать о нем раньше…
Я написал эту страницу, чтобы попытаться объяснить науку, лежащую в основе этого мема. В этом есть доля правды, но есть и некоторые вещи, которые ученые, изучающие психологию языка (психолингвисты), считают неверными. Наиболее поразительно, что недавняя статья показала замедление на 11%, когда люди читают слова с измененным порядком внутренних букв:
Кейт Рейнер, Сара Дж. Уайт, Ребекка Л. Джонсон и Саймон П. Ливерседж
Psychological Science, 17(3), 192-193
В то же время люди довольно часто не замечают этих орфографических ошибок, и 11%-ная стоимость меньше, чем наблюдалась бы при замене букв или изменении порядка их написания. внешние буквы. Итак, в меме есть элементы правды, но в целом он ложен.
Я собираюсь разобрать мем, по одной строке за раз, чтобы проиллюстрировать эти моменты, указывая на то, что я считаю важным исследованием роли порядка букв при чтении. Опять же, это только мой взгляд на нынешнее состояние исследований чтения, связанных с этим мемом. Если вы считаете, что я пропустил что-то важное, дайте мне знать [[email protected]?subject=subject%3DCmabrigde].
Опять же, это только мой взгляд на нынешнее состояние исследований чтения, связанных с этим мемом. Если вы считаете, что я пропустил что-то важное, дайте мне знать [[email protected]?subject=subject%3DCmabrigde].
1) aoccdrnig to rscheearch в Cmabrigde Uinervtisy… Согласно исследованию (sic) в Кембриджском университете
В Кембридже, Великобритания, есть несколько групп, занимающихся исследованиями в области языка. Есть группа, в которой я работаю (отделение познания и наук о мозге), есть также группы на кафедре экспериментальной психологии, в первую очередь Центр речи и языка (где я раньше работал). Есть также исследователи языка в области фонетики, Исследовательского центра английского языка и прикладной лингвистики и в Университете Англии Раскина.
Насколько мне известно, в Кембридже, Великобритания, в настоящее время нет никого, кто занимался бы исследованием этой темы. Возможно, в Кембридже, штат Массачусетс, США, есть люди, ответственные за это исследование, но я о них не знаю. Если вы знаете другое, сообщите мне [[email protected]?subject=Cmabrigde].
Если вы знаете другое, сообщите мне [[email protected]?subject=Cmabrigde].
Обновление:
Я нашел веб-страницу, на которой отслеживалась первоначальная демонстрация эффекта рандомизации писем Грэму Роулинсону. Грэм написал письмо в New Scientist в 1999 (в ответ на статью Сабери и Перро (Nature, 1999) об эффекте обращения коротких фрагментов речи). В нем Грэм говорит:
Это напоминает мне мою кандидатскую диссертацию в Ноттингемском университете (1976), которая показала, что случайное расположение букв в середине слов практически не влияет на способность опытных читателей понимать текст. Действительно, один быстрый читатель заметил только четыре или пять ошибок на странице A4 запутанного текста.
Вполне возможно, что благодаря широкой огласке в Интернете исследования доктора Роулинсона станут более широко читаемыми в будущем. Для тех, кто хочет процитировать это в своем собственном исследовании, полная ссылка:
Rawlinson, GE (1976) Значение положения буквы в распознавании слов. Неопубликованная докторская диссертация, факультет психологии, Ноттингемский университет, Ноттингем, Великобритания.
Неопубликованная докторская диссертация, факультет психологии, Ноттингемский университет, Ноттингем, Великобритания.
Обновление 2:
Грэм очень любезно прислал мне резюме своей дипломной работы.
2) Не имеет значения, в каком порядке находятся буквы в строке, единственная важная вещь заключается в том, что первая и последняя должны быть справа… не имеет значения, в каком порядке буквы в строке слово есть, главное, чтобы первая и последняя буквы были на нужном месте
Это явно неправильно. Например, сравните следующие три предложения:
1) Поезд на площади рядом с зданием ООН, хадукертарес в Багахде в понедельник убил бандита и офицера полиции Ирака
см. вложения многих людей
3) Дооткр нацелился на маглтеуансра тагенского кесаря пинта, который дейд этфр хатоспил дург блендур
Все три предложения были рандомизированы в соответствии с «правилами», описанными в меме. Первая и последняя буквы остались на прежнем месте, а все остальные буквы были перемещены. Тем не менее, я подозреваю, что ваш опыт такой же, как и мой, а именно: тексты становятся все труднее читать. Если вы застряли, оригинальные предложения вставлены внизу этой статьи.
Первая и последняя буквы остались на прежнем месте, а все остальные буквы были перемещены. Тем не менее, я подозреваю, что ваш опыт такой же, как и мой, а именно: тексты становятся все труднее читать. Если вы застряли, оригинальные предложения вставлены внизу этой статьи.
Надеюсь, эти демонстрации убедили вас в том, что в некоторых случаях бывает очень трудно понять смысл предложений с перемешанными словами. Понятно, что первая и последняя буквы — не единственное, что вы используете при чтении текста. Если бы это действительно было так, как бы вы определили разницу между такими парами слов, как «соль» и «планка»?
Я собираюсь перечислить некоторые способы, которыми, по моему мнению, автор(ы) этого мема мог манипулировать беспорядочным текстом, чтобы сделать его относительно легко читаемым. Это также поможет составить список факторов, которые, по нашему мнению, могут быть важны для определения легкости или сложности чтения беспорядочного текста в целом.
Однако в психологии чтения до сих пор ведутся настоящие споры о том, какую именно информацию мы используем при чтении. Я не знаю, какая часть этой литературы была известна доктору Роулинсону во время написания диссертации, но я думаю, что беспорядочный текст представляет собой аккуратную иллюстрацию некоторых источников информации, которые мы теперь считаем важными. Я собираюсь сделать обзор некоторых исследований, которые были сделаны, чтобы продемонстрировать это.
Я не знаю, какая часть этой литературы была известна доктору Роулинсону во время написания диссертации, но я думаю, что беспорядочный текст представляет собой аккуратную иллюстрацию некоторых источников информации, которые мы теперь считаем важными. Я собираюсь сделать обзор некоторых исследований, которые были сделаны, чтобы продемонстрировать это.
3) rset может быть toatl mses, и вы можете читать его без порбелма… остальное может быть полным беспорядком, и вы все равно можете прочитать его без проблем
Это предложение, как и остальная часть демонстрации, поразительно легко читается, несмотря на путаницу. Как вы видели выше, не все предложения, искаженные таким образом, так легко читать. Что делает эту фразу такой легкой? Мои коллеги и я предложили следующие свойства:
1) Короткие слова просты — слова из 2 или 3 букв вообще не меняются. Единственное изменение, которое возможно в четырехбуквенном слове, это поменять порядок средних букв, что не вызывает особых затруднений (см. 4).
4).
2) Функциональные слова (the, be, and, you и т. д.) остаются прежними — в основном потому, что они короткие, см. (1). Это действительно помогает читателю, сохраняя грамматическую структуру оригинала, помогая вам понять, какое слово может быть следующим. Это особенно важно при чтении беспорядочного текста — предсказуемые слова будет легче читать в этой ситуации.
3) Из 15 слов в этом предложении 8 все еще в правильном порядке. Однако, как читатель, вы можете этого не заметить, поскольку многие слова, которые остались нетронутыми, являются служебными словами, которые читатели, как правило, не замечают при чтении. Например, когда людей просят определить отдельные буквы в предложении, они с большей вероятностью пропустят буквы в служебных словах.
Хили, А. Ф. (1976). Ошибки обнаружения в слове The: Доказательства чтения единиц, больших, чем буквы. Журнал экспериментальной психологии: человеческое восприятие и производительность, 2, 235–242.
4) Транспозиции соседних букв (например, porbelm для задачи) легче читать, чем более отдаленные транспозиции (например, pborlem). Из исследований, в которых люди очень кратко читали слова, представленные на экране компьютера, мы знаем, что внешние буквы слов легче обнаружить, чем средние буквы, что подтверждает одну из идей, присутствующих в меме. Мы также знаем, что информацию о положении букв в середине слов обнаружить труднее и что допущенные ошибки, как правило, являются транспозициями.
Из исследований, в которых люди очень кратко читали слова, представленные на экране компьютера, мы знаем, что внешние буквы слов легче обнаружить, чем средние буквы, что подтверждает одну из идей, присутствующих в меме. Мы также знаем, что информацию о положении букв в середине слов обнаружить труднее и что допущенные ошибки, как правило, являются транспозициями.
McCusker, L.X., Gough, P.B., Bias, RG (1981) Распознавание слов изнутри наружу и снаружи внутрь. Journal of Experimental Psychology: Human Perception and Performance, 7(3), 538-551.
Одно из объяснений этого свойства системы чтения состоит в том, что оно вытекает из того факта, что положение внешней буквы труднее спутать с соседними буквами. Есть только одно направление, в котором может двигаться внешняя буква, и меньше соседних букв, чтобы «маскировать» внешнюю букву. Оба эти свойства естественным образом проявляются в модели нейронной сети, в которой буквы идентифицируются в разных местах искусственной сетчатки.
Шиллкок Р., Эллисон Т.М. и Монаган, П. (2000). Поведение фиксации глаз, лексическое хранение и визуальное распознавание слов в модели раздельной обработки. Психологический обзор 107, 824-851.
Учетная запись, предложенная Ричардом Шилкоком и его коллегами, также предполагает еще один механизм, который может работать в меме. Они предлагают модель распознавания слов, в которой каждое слово делится пополам, поскольку информация на сетчатке делится между двумя полушариями мозга, когда мы читаем. В некоторых симуляциях своей модели Ричард Шилкок имитирует эффект смешивания букв в каждой половине слова. Кажется, что сохранение букв в соответствующей половине слова снижает сложность чтения беспорядочного текста. Этот подход использовался при создании примера (1) выше, но не для (2) или (3).
5) Ни одно из слов, в которых переставлены буквы, не создает другое слово (wouthit vs witohut). Из существующих работ мы знаем, что слова, которые можно перепутать, поменяв местами внутренние буквы (например, соль и планка), читать труднее. Поэтому, чтобы сделать легко читаемое беспорядочное слово, вам следует избегать создания других слов.
Поэтому, чтобы сделать легко читаемое беспорядочное слово, вам следует избегать создания других слов.
Эндрюс, С. (1996) Процессы лексического поиска и выбора: эффекты путаницы с транспонированными буквами. Журнал памяти и языка, 35 (6), 775-800.
6) Использовались транспозиции, сохраняющие звучание исходного слова (например, toatl vs ttaol для total). Это поможет при чтении, поскольку мы часто обращаем внимание на звучание слов, даже когда читаем по смыслу:
Ван-Орден, Г.К. (1987) РЯДЫ — это РОЗА: правописание, звук и чтение. Память и познание, 15 (3), 181-198.
7) Текст достаточно предсказуем. Например, зная первые несколько слов предложения, вы можете угадать, какие слова следуют дальше (даже имея очень мало информации по буквам в слове). Мы знаем, что контекст играет важную роль в понимании речи, которая искажена или представлена в шуме, то же самое, вероятно, верно и для написанного текста, который был перемешан:
Миллер, Г. А., Хейз, Г. А. , и Лихтен, В. (1951). Разборчивость речи как функция контекста тестовых материалов. Журнал экспериментальной психологии, 41, 329-335.
, и Лихтен, В. (1951). Разборчивость речи как функция контекста тестовых материалов. Журнал экспериментальной психологии, 41, 329-335.
4) Это связано с тем, что человек не распознает истину через истлеф, а пишет как целое… Это потому, что человеческий разум не читает каждую букву отдельно по слову в целом.
В этом предложении есть две идеи. По сути, автор прав, люди обычно не читают каждую букву в слове по отдельности, за исключением относительно редкого состояния после черепно-мозговой травмы, известного как чтение по буквам, как описано ниже:0007
Уоррингтон, Э.К., и Шаллис, Т. (1980). Словоформная дислексия. Мозг, 103, 99–112.
Имеются также данные, свидетельствующие о том, что информация в форме целого слова играет важную роль при чтении. Например, «CaSe MixiNg» существенно замедляет чтение:
Mayall, K., Humphreys, G.W., & Olson, A. (1997). Нарушение обработки слов или букв? Происхождение эффектов смешения регистров. Журнал экспериментальной психологии: обучение, память и познание, 23, 1275–1286.
Однако, поскольку «форма слова» включает информацию о положении внутренних букв (особенно там, где они содержат восходящие и нисходящие элементы), форма слова будет нарушена транспозициями.
После краткого представления письменных слов люди часто лучше угадывают, какое слово они видели, а не угадывают отдельные буквы в этом слове («Эффект превосходства слова»): осмысленности стимульного материала. Журнал экспериментальной психологии. 81(2), 275-280.
Однако эта демонстрация не означает, что чтение не включает какой-либо процесс, происходящий на уровне отдельных букв. В недавней статье в журнале Nature представлены новые доказательства процессов на уровне букв при чтении слов:
Пелли, Д. Г., Фарелл, Б., Мур, Д. С. (2003) Замечательная неэффективность распознавания слов, Nature, 423, 752- 756.
В этой статье Пелли и его коллеги показывают, что при чтении слов, которые были искажены за счет представления каждой буквы в виде визуального шума (например, расстроенного телевизора), читатели не работают так же хорошо, как «идеальный наблюдатель», который может распознавать слова. только на основании их формы. Вместо этого их участники работают так же хорошо, как если бы они распознавали слова на основе их отдельных букв.
только на основании их формы. Вместо этого их участники работают так же хорошо, как если бы они распознавали слова на основе их отдельных букв.
Ясно, что спор о том, читаем ли мы информацию по отдельным буквам или по целым словам, далек от завершения. Демонстрация легкости или трудности чтения перемешанных текстов, по-видимому, играет важную роль в нашем понимании этого процесса. Например:
Переа, М., и Лупкер, С. Дж. (2003). Jugde активирует COURT? Эффекты смешения транспонированных букв при замаскированном ассоциативном прайминге. Память и познание.
Еще одна чрезвычайно актуальная статья, которая только что привлекла мое внимание, это:
Переа, М., и Лупкер, С.Дж. (2003). Эффекты смешения транспонированных букв при прайминге замаскированной формы. В S. Kinoshita и SJ Lupker (Eds.), Маскированное грунтование: состояние дел (стр. 97–120). Хов, Великобритания: Psychology Press.
Переа и Лупкер представили слова для лексического решения (настоящее ли это слово?) и измерили время реакции на нажатие одной из двух кнопок (да/нет). Этим целевым словам предшествует очень короткое представление (50 мс) другой цепочки букв, которая замаскирована и поэтому невидима для участников. Однако влияние этого замаскированного слова можно показать на времени отклика. Например, время отклика меньше, если перед USHER стоит «uhser», чем если перед ним стоит «ushre». То есть транспозиция средней буквы «штрихует» соседнее слово больше, чем транспозиция внешней буквы. То же явление, которое лежит в основе более ранней демонстрации.
Этим целевым словам предшествует очень короткое представление (50 мс) другой цепочки букв, которая замаскирована и поэтому невидима для участников. Однако влияние этого замаскированного слова можно показать на времени отклика. Например, время отклика меньше, если перед USHER стоит «uhser», чем если перед ним стоит «ushre». То есть транспозиция средней буквы «штрихует» соседнее слово больше, чем транспозиция внешней буквы. То же явление, которое лежит в основе более ранней демонстрации.
Буду признателен за любые комментарии и предложения людей на этой странице, независимо от вашего уровня знаний. Я постараюсь обновить эту страницу, добавив больше информации об интернет-мемах и связанных с ними работах по чтению, если людям это интересно. Возможно, когда-нибудь группа исследователей из Кембриджского университета совершит научный прорыв, изучая чтение беспорядочного текста…
Другие комментарии:
1) Тед Уорринг разместил ссылку на алгоритм, который намного лучше, чем люди в расшифровке зашифрованного текста. Это, пожалуй, неудивительно — я уверен, что я не единственный человек, который использовал компьютерную программу для решения особенно сложной анаграммы.
Это, пожалуй, неудивительно — я уверен, что я не единственный человек, который использовал компьютерную программу для решения особенно сложной анаграммы.
2) Брюс Мюррей из Обернского университета, Алабама, США, указывает на следующую цитату как на представителя направления исследований, показывающих, что орфографические ошибки (и перестановки букв) нарушают процесс чтения:
«Независимо от семантики, синтаксиса или орфографии». предсказуемость, глаз, кажется, обрабатывает отдельные буквы … Нарушения движений глаз взрослых читателей указывают на то, что зрительная система имеет тенденцию улавливать малейшие орфографические ошибки».
(от Адамса, М.Дж. (1990) Начинаем читать: размышления и изучение печати. Кембридж, Массачусетс: MIT Press, с. 101)
Здесь есть интересный момент, который заключается в том, что субъективное впечатление о трудности чтения, получаемое при чтении беспорядочного текста, может сильно отличаться от более объективного измерения трудности чтения, полученного с помощью айтрекера (устройства, измеряющего шаблон движений глаз при чтении печатного текста).
Брюс также указал, что исходный текст и некоторые обсуждения были размещены на «Справочной странице городских легенд».
3) Питер Хебельс создал программу на Visual Basic для создания перемешанных текстов. Как он говорит:
Я сделал хорошую программу с открытым исходным кодом на Visual Basic, эта программа может автоматически выполнять рандомизацию букв для вас. Он рандомизирует только средние буквы слова, не меняет местами первую и последнюю буквы, а также не затрагивает специальные символы, такие как запятые и точки. Вы можете скачать программу и исходный код здесь:
http://home.zonnet.nl/hebels13/letterreplacer.zip
Вам потребуются файлы среды выполнения Visual Basic, если вы хотите запустить исполняемый файл, установку для этих файлов можно найти здесь:
http://download.microsoft.com/download/vb60pro/ install/6/Win98Me/EN-US/VBRun60.exe
4) Clive Tooth нашел, возможно, наиболее двусмысленное беспорядочное предложение (с использованием таких слов, как «соль», которое при транспонировании становится «планкой»)
«The sprehas has ponits и патлы»
Это может выглядеть как. ..
..
У шерпов были крючья и пластины.
Формирователи имели заострения и складки.
У серафимов были пинто и лепестки.
В сферах были пино и поддоны.
На копьях были горшки и пельты.
Клайв перечисляет некоторые из наиболее неясных слов в этом наборе возможных прочтений:
палитра: пали (часть цветка травы)
пельта: щитки
пино: виноград
потины: медные сплавы
сфаерс sphears: обе старые формы «сфер»
5) Стивен Сакс написал CGI-сценарий для смешивания текста. Просто введите свой текст на странице www и нажмите кнопку для нового зашифрованного текста.
Благодарности:
Спасибо Maarten van Casteren, Kathy Rastle и Tim Rogers за комментарии и предложения на этой странице.
——————-
Примеры предложений:
1) Автомобиль взорвался на контрольно-пропускном пункте полиции возле штаб-квартиры ООН в Багдаде в понедельник, в результате чего погиб террорист и Офицер полиции Ирака
2) Значительное повышение муниципальных налогов в этом году сократило доходы многих пенсионеров
3) Врач признал непредумышленное убийство подростка, больного раком, который умер после ошибки в больнице, связанной с лекарствами.
Все это пришло из BBC News 22 сентября 2003 года. В конечном счете, это не имеет значения, в чем дело, а что есть в мире, единственно важным является то, что первый и последний должны быть в правильном месте. Это связано с тем, что люди не искажаются истлефом, а рождаются как мир».
Скорее всего, вы тоже это понимаете. Он утверждает, что порядок букв в данном слове не имеет значения, если первая и последняя буквы каждого слова находятся на своих местах.
Вы можете читать слова, потому что человеческий разум читает слова целиком, а не по буквам.
Ну, так оно и есть. Но в то время как это развлекает и повышает эго (то есть, если вы можете прочитать это), это не совсем так.
• Щелкните здесь, чтобы посетить Центр естественных наук FOXNews.com.
Электронное письмо, хотя и частично правильное в своей общей гипотетике — гм, гипотезе — «очень безответственно в нескольких важных отношениях», — говорит Денис Пелли, профессор психологии и неврологии в Нью-Йоркском университете.
Прежде всего — упс — в Кембриджском университете никогда не проводилось исследования. И в этом заключается сказка.
Первоначально электронное письмо было разослано без упоминания Кембриджа; это было добавлено после того, как Times of London взяла интервью у нейропсихолога из Кембриджа для комментариев.
Мэтт Дэвис, старший научный сотрудник отдела познания и изучения мозга Кембриджского университета, потратил некоторое время на выяснение происхождения этой истории с транспозицией букв.
Он обнаружил, что это происходит из письма, написанного в 1999 году Грэмом Роулинсоном, специалистом по детскому развитию и педагогической психологии, в журнал New Scientist в ответ на статью, написанную о последствиях обращения коротких отрывков речи.
В своем письме Роулинсон, которого FoxNews.com не смог разыскать, написал, что статья «напоминает мне мою докторскую диссертацию в Ноттингемском университете, которая показала, что рандомизация букв в середине слов практически не повлияла на способность квалифицированных читателей понимать текст».
Позже Роулинсон связался с Дэвисом, который создал веб-сайт для решения проблем, связанных с часто пересылаемой электронной почтой, чтобы объяснить свой комментарий и исследование диссертации.
«Очевидно, что первая и последняя буквы — не единственное, что вы используете при чтении текста», — написал он. «Если бы это было так, как бы вы определили разницу между такими парами слов, как «соль» и «планка»?
Также следует отметить, как один комментатор на веб-сайте Дэвиса, Клайв Зуб, написал, что одна перестановка может привести к множеству разных слов, и хотя вы можете принять во внимание контекст предложения, все равно нельзя быть уверенным об истинном намерении автора в выборе слова.
Например, переставленные буквы слова «понитс» могут составить любое из пяти различных слов: «питоны», «пойнты», «пинтос», «потины» и «пинотс».
Рассылаемое электронное письмо само по себе также вводит в заблуждение, сказал Роулинсон, потому что кажется, что оно написано для усиления желаемого эффекта, чтобы еще больше доказать свою точку зрения.
Роулинсон отмечает, что слова, состоящие из двух или трех букв, вообще не меняются, что делает их полностью понятными.
В электронной почте почти половина (31 из 69) слова написаны правильно. Неизменные слова также часто являются «служебными словами» — the, you, me, but и — которые помогают сохранить грамматику предложений в основном неизменной.
Электронное письмо также переставляет соседние буквы, что облегчает чтение слов. Например, «вещь» пишется как «tihng», а не «tnihg»; «проблема» пишется как «porbelm», а не «pbleorm».
Наконец, говорит Роулинсон, формулировка, используемая в самом электронном письме, вполне предсказуема. Предложения просты, и, учитывая неизменные слова, можно легко вывести их значение.
Другой эксперт в этой конкретной области, Кит Рейнер, профессор психологии и директор лаборатории Rayner Eyetracking Lab в Калифорнийском университете в Сан-Диего, сказал: «Есть доля правды в электронной почте, поскольку люди могут читать предложения, в которых буквы перемешаны. Но всегда есть цена (т. е. они никогда не читают их так же быстро и эффективно, как обычный текст)».
Но всегда есть цена (т. е. они никогда не читают их так же быстро и эффективно, как обычный текст)».
Рейнер и его коллеги провели эксперимент, в ходе которого они попросили студентов колледжа Даремского университета прочитать 80 предложений с переставленными буквами. Перестановка букв в словах привела к снижению скорости чтения у большинства участников.
Студенты читали 255 слов в минуту, когда предложения были нормальными, и 227 слов в минуту, когда буквы были переставлены, что означает 12-процентное снижение общей скорости чтения.
«Хотя может показаться, что текст с переставленными буквами легко читать, — писал Рейнер, — чтение такого текста всегда сопряжено с затратами по сравнению с обычным текстом».
Дэвис, которому, кажется, надоело это электронное письмо, особенно из-за того, что в нем добавлено имя Кембриджа, сказал: «Мораль этой истории (по крайней мере, в том, что касается Cmabrdige), заключается в том, что напечатанную неправду очень трудно скрыть. .»
.»
Но он видит положительную сторону в том факте, что простое перенаправленное электронное письмо пролило свет на проблему, близкую и важную для его научных интересов.
«Что несомненно верно, так это то, что количество научных исследований перепутанных букв и порядка букв при чтении значительно увеличилось с тех пор, как электронная почта начала циркулировать», — сказал он.
Теперь, когда вы знаете всю историю, вы будете хорошо вооружены «настоящими» фактами, когда этот «факт» всплывет во время коктейля.
Только отвечай разумно.
И помните, что следует избегать чрезмерного употребления алкоголя.
Может ли наш мозг действительно читать беспорядочные слова, если первая и последняя буквы правильные? : ScienceAlert
Вы, наверное, уже видели классическую часть «веселых интернет-интересов» на изображении выше — она циркулирует по крайней мере с 2003 года.
На первый взгляд, это кажется законным. Потому что вы действительно можете это прочитать, верно? Но, хотя в меме есть доля правды, реальность всегда сложнее.
Мем утверждает со ссылкой на неназванного ученого из Кембриджа, что если первая и последняя буквы слова стоят на правильных местах, вы все равно можете прочитать фрагмент текста.
Мы разобрали сообщение дословно.
«Согласно исследованию [так в оригинале] в Кембриджском университете, не имеет значения, в каком порядке стоят буквы в слове, важно [так в оригинале] только то, чтобы первая и последняя буквы были на нужном месте. Остальное может быть полный беспорядок, и вы все равно можете прочитать его без проблем. Это потому, что человеческий разум читает не каждую букву отдельно, а слово в целом».
На самом деле, кембриджского исследователя никогда не было (самая ранняя форма мема фактически распространялась без этого конкретного дополнения), но есть некоторая наука, объясняющая, почему мы можем читать этот конкретный беспорядочный текст.
Явление получило несколько ироничное название «Типогликемия», и оно работает, потому что наш мозг полагается не только на то, что он видит, но и на то, что мы ожидаем увидеть.
В 2011 году исследователи из Университета Глазго, проводя несвязанные исследования, обнаружили, что когда что-то скрыто от глаз или неясно для глаз, человеческий разум может предсказать, что, по их мнению, они увидят, и заполнить пробелы.
«По сути, наш мозг создает невероятно сложную головоломку, используя любые кусочки, к которым он может получить доступ», — объяснил исследователь Фрейзер Смит. «Они обеспечиваются контекстом, в котором мы их видим, нашими воспоминаниями и другими нашими чувствами».
Однако мем — это только часть истории. Мэтт Дэвис, исследователь из отдела познания и изучения мозга MRC Кембриджского университета, хотел разобраться в «Кембриджском» утверждении, поскольку считал, что должен был слышать об этом исследовании раньше.
Ему удалось отследить первоначальную демонстрацию рандомизации букв до исследователя по имени Грэм Роулинсон, который написал свою докторскую диссертацию на эту тему в Ноттингемском университете в 1976 году.
Он провел 16 экспериментов и обнаружил, что да, люди могут распознавать слова, если средние буквы были перепутаны, но, как указывает Дэвис, есть несколько предостережений.
- Это гораздо проще сделать с короткими словами, вероятно, потому, что меньше переменных.
- Функциональные слова, обеспечивающие грамматическую структуру, такие как and, the и a, как правило, остаются неизменными, потому что они очень короткие. Это помогает читателю сохранить структуру, упрощая прогнозирование.
- Переключение соседних букв, например porbelm на задачу , легче перевести, чем переключение более дальних букв, как plorebm .
- Ни одно из слов в меме не перемешано, чтобы получить другое слово — Дэвис приводит пример без против без . Это связано с тем, что слова, которые различаются только положением двух соседних букв, например спокойный и моллюск или пробный и след , труднее читать.
- Слова все более-менее сохранили свое первоначальное звучание — порядок заменен на oredr вместо или , например.
- Текст достаточно предсказуем.

Это также помогает совмещать двойные буквы. Например, гораздо проще расшифровать aoccdrnig и mttaer , чем adcinorcg и metatr .
Есть основания полагать, что восходящие и нисходящие элементы также играют роль — то, что мы распознаем, — это форма слова. Вот почему текст смешанного регистра, такой как чередование заглавных букв, так трудно читать — он радикально меняет форму слова, даже если все буквы стоят на своих местах.
Если вы поэкспериментируете с этим генератором, то сами увидите, насколько правильная рандомизация средних букв слов может сделать текст крайне трудным для чтения. Попробуйте это:
Adkmgowenlcent — который имеет место в новой версии mcie etpnremxeis taht ddin’t iotdnure scuh mantiotus — не является единственным rtoatriecn своих предыдущих фиджиннов, но он не имеет никакого пути к shnwiog bleev bleev blerm taht aalrm sdnuoed в fsrit plcae.
Может быть, это немного жульничает — это абзац из статьи ScienceAlert о CRISPR.